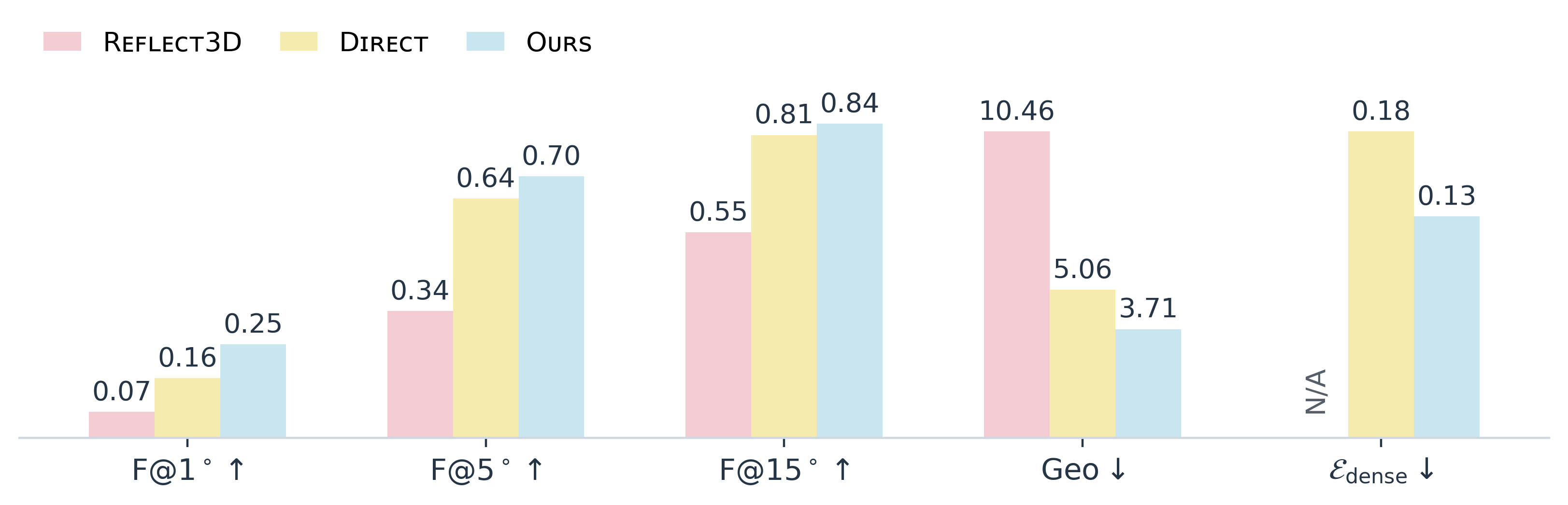Symmetry detection is a fundamental problem in computer vision, and symmetries serve as powerful priors for downstream tasks.
However, existing learning-based methods for detecting 3D symmetries from single images have been almost exclusively trained
and evaluated on object-centric or synthetic datasets, and therefore fail to generalize to real-world scenes. Furthermore,
because monocular inputs are inherently scale ambiguous, localizing a 3D symmetry plane is ill-posed, and many prior methods
only predict plane orientation.
We address these limitations by introducing the first framework for detecting 3D-grounded reflectional symmetries
from single, in-the-wild RGB images, with a focus on architectural landmarks. Our approach has two key components:
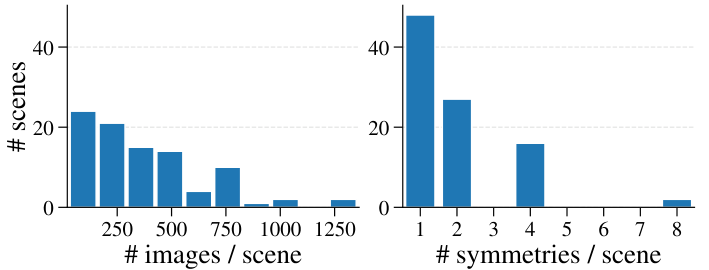
(1) a scalable annotation pipeline that automatically curates ArchSym, a large-scale dataset
of architectural symmetries, from SfM reconstructions via cross-view image matching; and
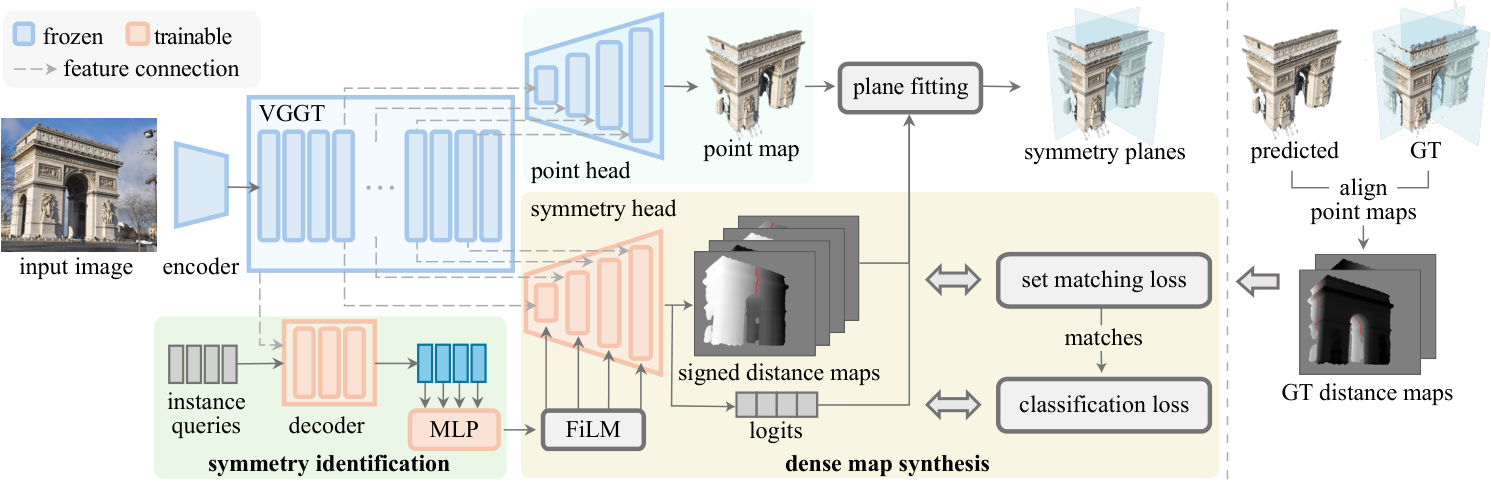
(2) a single-view symmetry detector that localizes symmetries in 3D by parameterizing them as signed distance maps defined
relative to predicted scene geometry. We validate the annotation pipeline against geometry-based alternatives and show that
the detector significantly outperforms state-of-the-art baselines on the new benchmark.